- Hbase开启GZIP压缩 摘要: 由于本人在阿里云存储的是一些文章,文章的访问频次一般,所以平时使用CPU的时间不算密集,且对于在阿里云上使用nas来说,存储越小花费就越小,所以就准备开启GZIP压缩。另外也是因为当时搭建hadoop集群的时候没有snappy的编译库。以下是Google几年前发布的一组测试数据(数据有些老了,有人近期做过测试... 发表于 2020-08-29 11:09 阅读(5280) 评论(0)
- hbase 主动做major_compact减少存储 摘要: #当修改数据,发现hbase占用空间过大时,可以手动触发major_compacthbase shellmajor_compact 'itdaan:post'... 发表于 2020-08-29 10:46 阅读(6401) 评论(0)
-
大数据
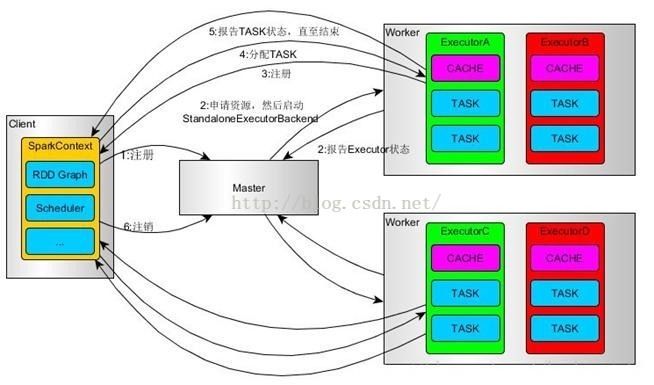
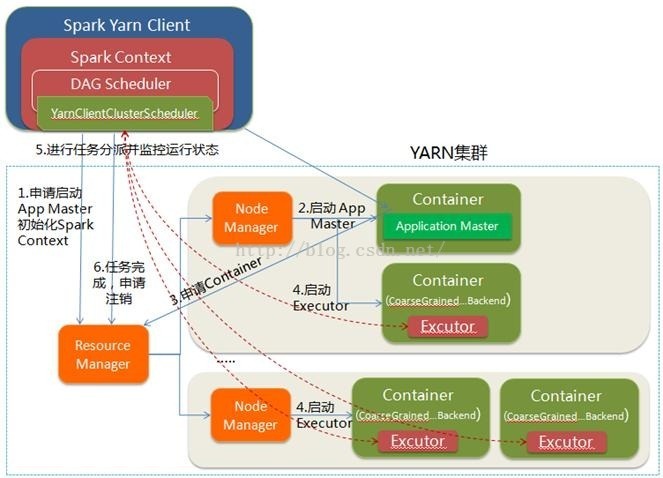
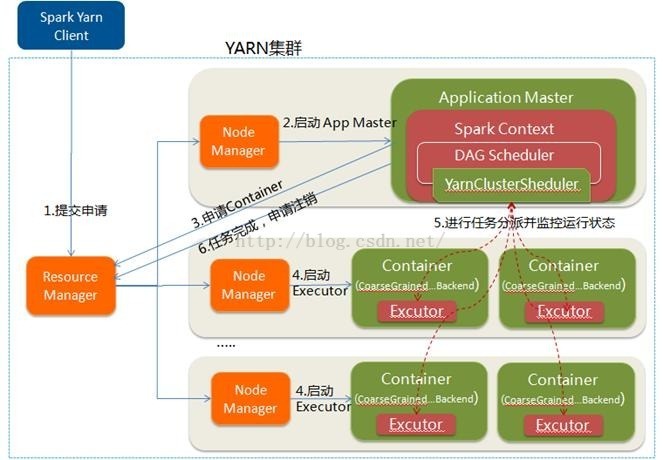
摘要: 1、 NAMENODE职责(1)负责客户端请求的响应(2)元数据的管理(查询,修改)2、元数据的存储机制A、内存中有一份完整的元数据(内存metadata)B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)C、用于衔接内存metadata和持久化元数据镜像fsimag...
 发表于 2020-06-20 21:12 阅读(5360) 评论(0)
发表于 2020-06-20 21:12 阅读(5360) 评论(0)
- spark为什么比hadoop要快? 摘要: 1、消除了冗余的HDFS读写Hadoop每次shuffle操作后,必须写到磁盘,而Spark在shuffle后不一定落盘,可以cache到内存中,以便迭代时使用。如果操作复杂,很多的shufle操作,那么Hadoop的读写IO时间会大大增加。2、消除了冗余的MapReduce阶段Hadoop的shuffle操... 发表于 2020-03-06 14:52 阅读(1724) 评论(0)
- Hive通过正则获取匹配的内容 摘要: 1、使用举例:regexp_extract(field,'(1[0-9]{10})',0) 获取手机号部分。field字段中含有手机号,'(1[0-9]{10})'是手机号的正则,0表示第一个满足的字符串;2、使用正则作为过滤条件:mobile regexp '^1[0-9]{10}'。... 发表于 2020-03-02 16:31 阅读(2102) 评论(0)
- Hive shell终端查询条件乱码的问题解决 摘要: 在服务上打开Hive Shell客户端,经常需要输入中文条件,但是每次都遇上输入中文乱码的问题。这个时候我想到了一个办法,那就是将中文URL编码,然后再解码作为查询条件的值。例如:我需要查询公司名称为“饭店”的记录原本查询SQL应该如下:select * from company where company_... 发表于 2020-02-24 16:49 阅读(1674) 评论(0)
- Hive Schema version 1.2.0 does not match metastore's schema version 2.3.0 摘要: 使用pyspark访问hive,出现问题:Hive Schema version 1.2.0 does not match metastore's schema version 2.3.0这是因为spark2.3.1默认支持1.x,所以当升级了hive后,就会报这个错。查了网上有两种解决方案:1、修改数据库配... 发表于 2020-01-15 20:03 阅读(2016) 评论(0)
- xgboost4j spark 打包libxgboost4j.so的命令 摘要: 1、 首先安装gcc 4.9.3安装步骤见:https://imzhangjie.cn/article/171.html 2、然后到达xgboost的源码目录执行:make config=make/config.mk3、最后编译libxgboost4j.so#在jvm-packages目录下创建lib目录mk... 发表于 2020-01-07 20:26 阅读(1902) 评论(1)
- 编译 xgboost 不编译 xgboost4j 下的JNI库libxgboost4j.so的问题解决 摘要: cmake 3.14.6gcc 4.8.5xgboost 0.72今天照着官网编译xgboost的源码,发现一个问题,xgboost4j下的native包没有编译。git clone --recursive https://github.com/dmlc/xgboostcd xgboostmkdir bui... 发表于 2020-01-03 19:44 阅读(2284) 评论(0)
- 重新设置hdfs某个路径下的备份数量 摘要: 有时候,我们为了节省集群的存储空间,需要减少hdfs的备份次数。这时候需要用到一个命令。例如:我需要将hdfs目录/data下的文件的备份改为2份hdfs dfs -setrep 2 -R -w /data/即可。... 发表于 2019-12-31 18:20 阅读(2217) 评论(0)

仧尐
用专业的技术,做有益的事情
Powered by IMZHANGJIE.CN Copyright © 2015-2025 粤ICP备14056181号