Positive-unlabeled learning
概要:
半监督学习(semi-supervised learning)
七夕节到了,你是不是遇到了这样一个难题,该送什么礼物给女朋友呢?假设你已经知道一堆她喜欢的物品列表(从她的购物车中得知),土豪朋友当然就是全买买买。但是对于新时代女性来说,这样的行为一点新意也没有,虽然你买的东西都是她故意让你看到。作为一个有心的人来说,能不能从她目前想买的东西中推断出她将来会买什么,才是重要的。假如突然给她买了一件她正想要的东西,但是不在她的购物车中,是不是就给了她一个很大的惊喜?
标准的supervised machine learning似乎是解决这个问题的好办法。通过比较正例(positive samples, 即她喜欢的东西)和反例(negative samples,即她不喜欢的东西)的区别,你可以设计一个算法来预测其他物品被她喜欢的概率。
然而,通常她很少会提起她不喜欢的东西。这样你就只有很少的negative samples来进行训练你的机器学习模型。这样模型的效果就会很差。如果模型把一个她非常讨厌的物品误判为她喜欢的物品,可以想象你的下场。那该怎么办呢?
这个时候就可以使用半监督学习(semisupervised machine learning)方法了。半监督学习可以不仅利用了她喜欢和不喜欢的物品的特征,而且还使用她从来没有评价过的物品(未标记的物品,unlabeled samples)的特征。令人惊讶的是,在这种情况下,可以有效地提高模型预测的准确性。
要了解未标记物品如何帮助我们开发预测模型,请参考下面的一幅图。
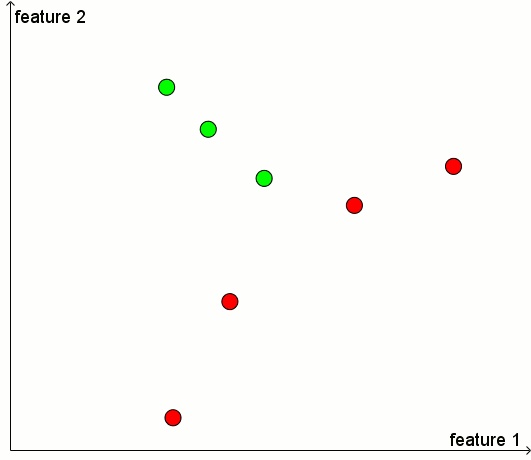
假设我们有一些positive samples(以绿色显示)和一些negative samples(以红色显示)。 为简单起见,假设每个sample都由两个特征描述(分别为横纵坐标)。 当我们使用一个模型来预测一个sample是正还是负时,就是将特征平面划分为两个区域,其中在一个区域中为正,在另一个区域中为负。关于如何划分特征平面,这取决于我们是否知道未标记物品(以灰色显示)的位置。
PU learning
PU learning (positive unlabeled learning)是半监督学习的一个重要分支,其中唯一可用的标记数据是正样本(喜欢的物品)。正如一个人为什么要谈论她不喜欢的东西?在这种情况下,标准的监督机器学习方法将是无效的,因为任何标准模型算法都需要正面和负面的例子来训练。但是,如果我们能够聪明地利用这些未标记的数据,那么它们将变得非常有用。
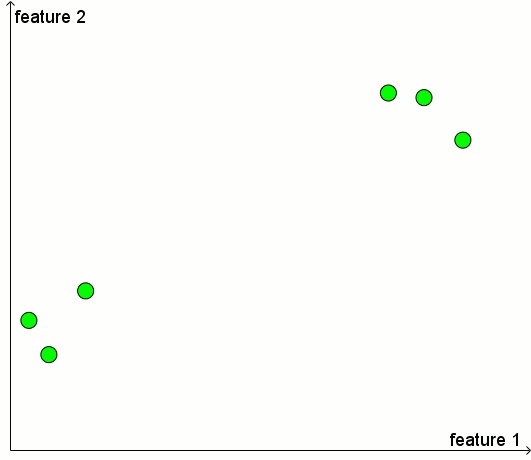
仔细看一下图2。我们有一些positive samples(以绿色显示),但是没有negative samples。我们必须将特征平面划分为两个区域,其中一个区域中为正,另一个区域中为负。如果我们知道未标记物品的位置,那么我们就能够做出一个与众不同的决定!
PU learning的一些技巧
人们对开发PU learning的方法一直非常感兴趣。 由于标准机器学习问题(利用大量正面和负面样本用于训练模型)是一个经过充分探索的领域,因此有许多解决方法经过巧妙调整,来进行PU learning。
下面对这些技巧进行简要的总结。
1、直接利用标准分类方法
最经常使用的PU learning方法或许是这样的:将正样本和未标记样本分别看作是positive samples和negative samples, 然后利用这些数据训练一个标准分类器。分类器将为每个物品打一个分数(概率值)。通常正样本分数高于负样本的分数。因此对于那些未标记的物品,分数较高的最有可能为positive。
这种朴素的方法在文献Learning classifiers from only positive and unlabeled data 中有介绍。该论文的核心结果是,在某些基本假设下(虽然对于现实生活目的而言可能稍微不合理),合理利用正例和未贴标签数据进行训练得到的标准分类器应该能够给出与实际正确分数成正比的分数。
正如作者们所说, “This means that if the [hypothetically properly trained] classifier is only used to rank examples according to the chance that they belong to [the positives], then the classifier [trained on positive and unlabeled data] can be used directly instead.”
2、PU bagging
一个更加复杂的方法来解决PU问题是采用bagging的变种:
a)、通过将所有正样本和未标记样本进行随机组合来创建训练集。
b)、利用这个“bootstrap”样本来构建分类器,分别将正样本和未标记样本视为positive和negative。
c)、将分类器应用于不在训练集中的未标记样本 - OOB(“out of bag”)- 并记录其分数。
d)、重复上述三个步骤,最后为每个样本的分数为OOB分数的平均值。
描述这种方法的一篇论文是 A bagging SVM to learn from positive and unlabeled examples 。 这篇文章的作者说, “the method can match and even outperform the performance of state-of-the-art methods for PU learning, particularly when the number of positive examples is limited and the fraction of negatives among the unlabeled examples is small. The proposed method can also run considerably faster than state-of-the-art methods, particularly when the set of unlabeled examples is large.”
3、Two-step approaches
大部分的PU learning策略属于 “two-step approaches”。最近的一篇介绍这些方法的论文是 An Evaluation of Two-Step Techniques for Positive-Unlabeled Learning in Text Classification 。
以下是这种方法的“两个步骤”:
a)、识别可以百分之百标记为negative的未标记样本子集(上述论文的作者称这些样本为“reliable negatives”。)
b)、使用正负样本来训练标准分类器并将其应用于剩余的未标记样本。
通常,会将第二步的结果返回到第一步并重复上述步骤。 正如以上作者所述,“If the [reliable negative] set contains mostly negative documents and is sufficiently large, a learning algorithm… works very well and will be able to build a good classifier. But often a very small set of negative documents identified in step 1… then a learning algorithm iteratively runs till it converges or some stopping criterion is met.”
一个相似的方法在博客Introduction to Pseudo-Labelling : A Semi-Supervised learning technique中给出,但是它具体不是针对PU问题来设计的。
4、Positive unlabeled random forest
这里值得一提的关于PU learning的最新一个发展是文献 Towards Positive Unlabeled Learning for Parallel Data Mining: A Random Forest Framework 中提出的一种算法。
根据作者所述,“The proposed framework, termed PURF (Positive Unlabeled Random Forest), is able to learn from positive and unlabeled instances and achieve comparable classification performance with RF trained by fully labeled data through parallel computing according to experiments on both synthetic and real-world UCI datasets… This framework combines PU learning techniques including widely used PU information gain (PURF-IG) and newly developed PU Gini index (PURF-GI) with an extendable parallel computing algorithm (i.e. RF).”
更重要地是,作者提到他们已经“implemented PURF with Python based on the scikit-learn package,” 因此,如果代码能够开源的话,这将会是一个令人期待的工具。
上一篇:如何理解召回率与精确率?
下一篇:Java
