数据挖掘机器学习中相关概念
(1)决策树模型中用到的算法有ID3, C4.5和C5.0来生成树,ID3使用信息增益选择属性特征,C4.5选择信息增益率选择属性特征,CART选择GINI系数作为选择特征的方法。
(一)ID3算法
熵:表示随机变量的不确定性。
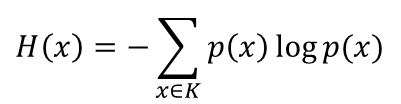
条件熵:在一个条件下,随机变量的不确定性。
信息增益:熵 - 条件熵
在一个条件下,信息不确定性减少的程度!
通俗地讲,X(明天下雨)是一个随机变量,X的熵可以算出来, Y(明天阴天)也是随机变量,在阴天情况下下雨的信息熵我们如果也知道的话(此处需要知道其联合概率分布或是通过数据估计)即是条件熵。
X的熵减去Y条件下X的熵,就是信息增益。具体解释:原本明天下雨的信息熵是2,条件熵是0.01(因为如果是阴天就下雨的概率很大,信息就少了),这样相减后为1.99。在获得阴天这个信息后,下雨信息不确定性减少了1.99,不确定减少了很多,所以信息增益大。也就是说,阴天这个信息对下雨来说是很重要的。
所以在特征选择的时候常常用信息增益,如果IG(信息增益大)的话那么这个特征对于分类来说很关键,决策树就是这样来找特征的。
参考资料:https://www.zhihu.com/question/22104055
(二)C4.5算法
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2) 在树构造过程中进行剪枝;
3) 能够完成对连续属性的离散化处理;
4) 能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
下一篇:如何理解召回率与精确率?
